write: 02/09/2025 / modified: 04/09/2025
Optical Character Recognition
Локальный проект, разработанный на python для внутреннего использования в организации. Представляет собой веб-приложение для оптического распознавания символов (OCR) на основе тюнингованной модели Qwen2.5-VL-3B-Instruct, интегрированной с vLLM-сервером.
Приложение поддерживает обработку изображений и PDF-файлов, предобработку изображений для улучшения качества, проверку орфографии на русском языке, а также экспорт результатов в Excel и Word.
Извлекает сложные таблицы из документов и преобразует их в таблицы в формате HTML. Распознаёт рукописный текст (если конечно это не рецепт выписанный неврологом).
Ключевые особенности:
- Асинхронная обработка задач с очередью.
- Поддержка многостраничных PDF.
- Предобработка изображений (CLAHE, медианный фильтр) для сканов низкого качества.
- Проверка орфографии с предложениями исправлений и пользовательским словарем.
- Фронтенд на HTML/JS с drag-and-drop и реал-тайм статусом.
- Мониторинг CPU, RAM, GPU и vLLM-сервера.
Технологический стек:
FastAPI,vLLM,Pillow,OpenCV,pandas,python-docx,BeautifulSoup,pdf2image.
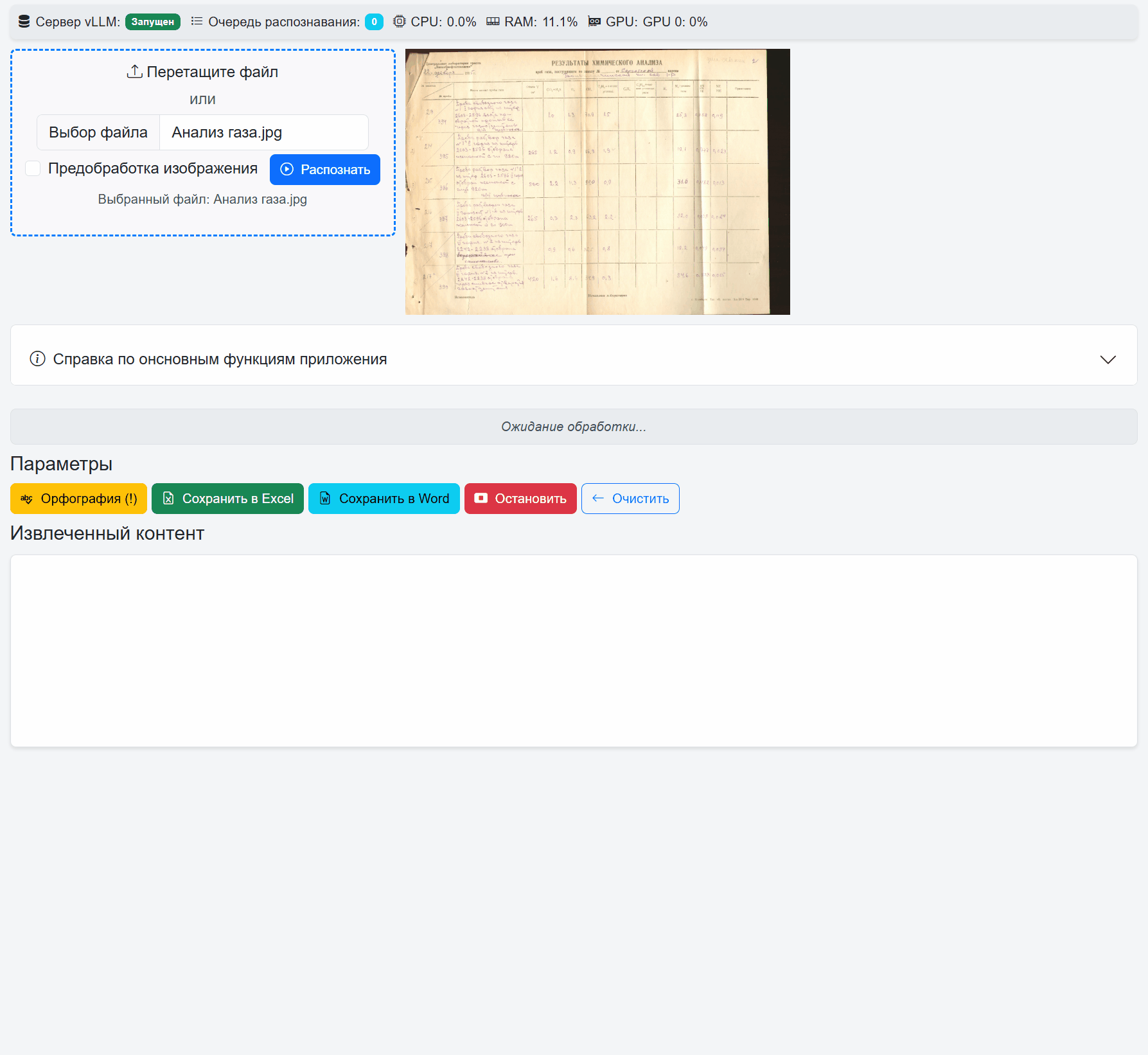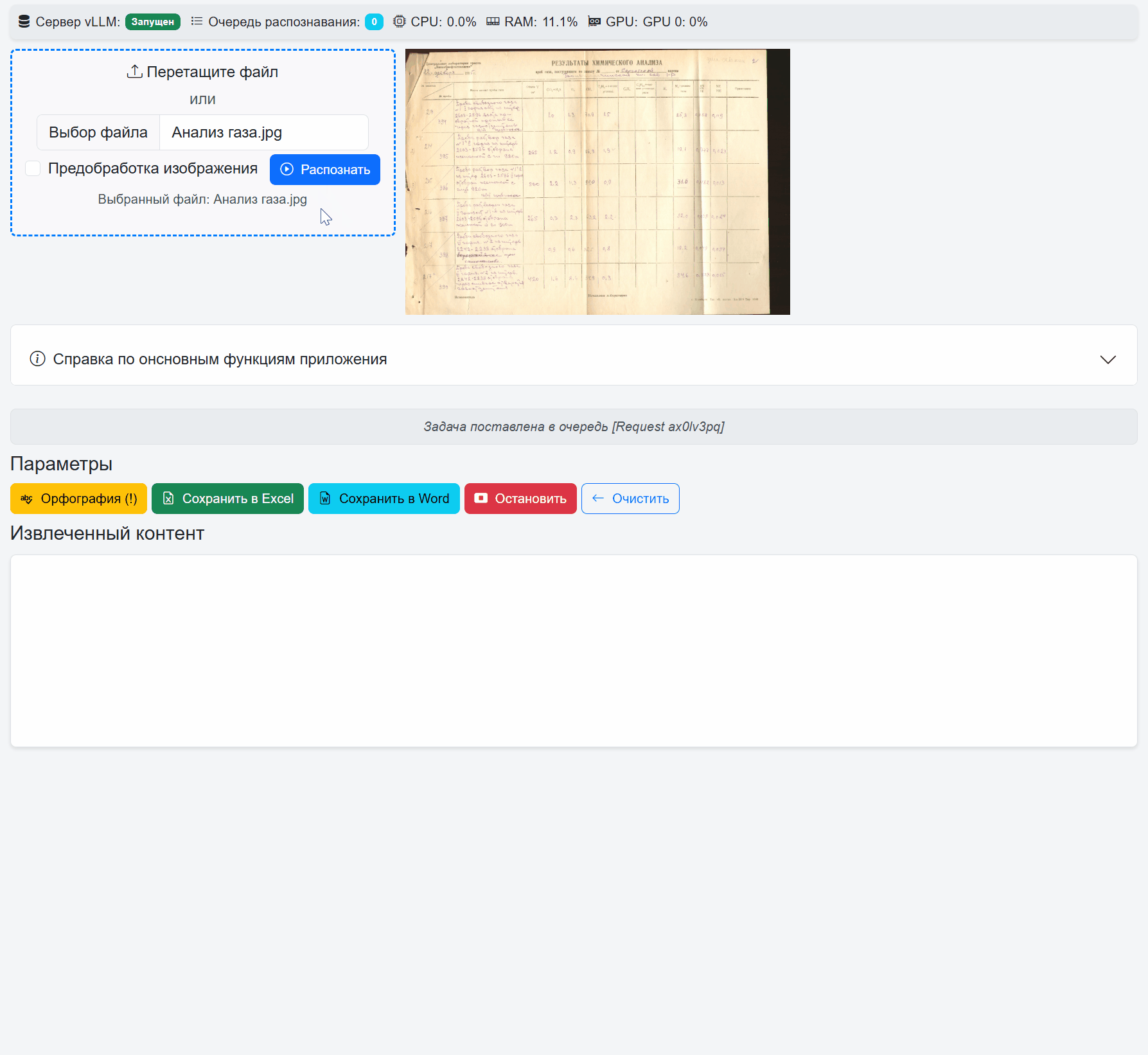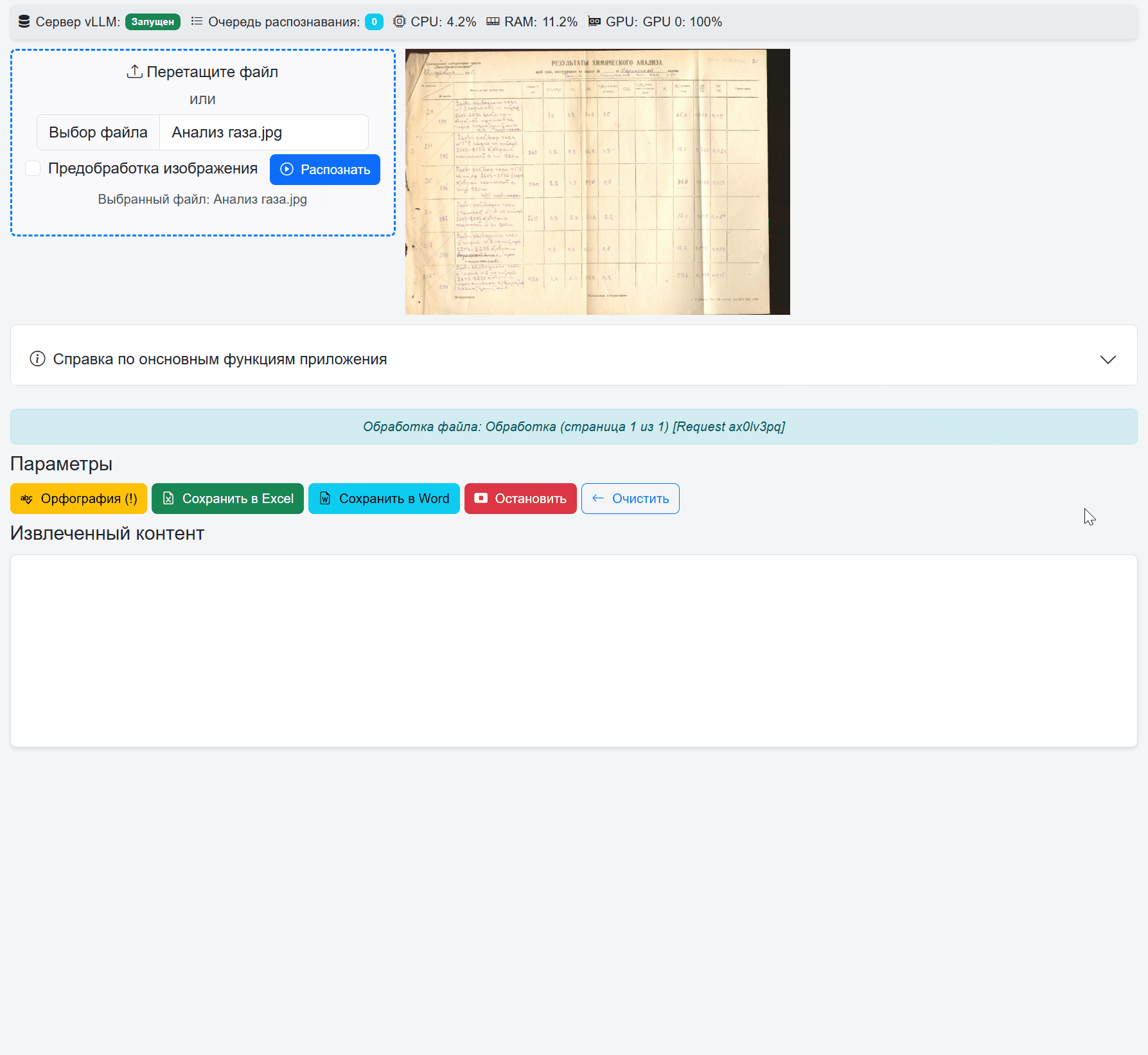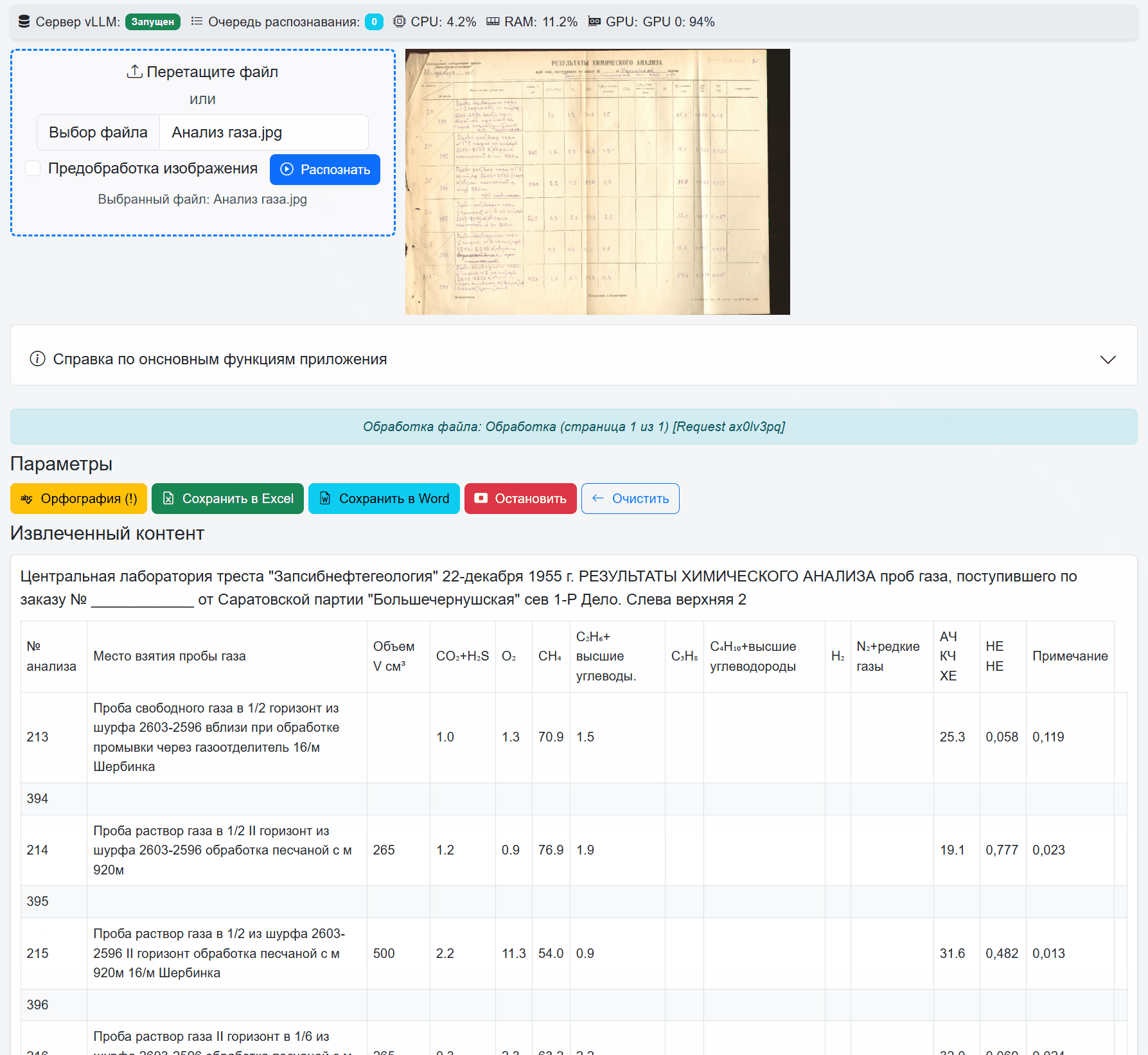
Результат распознавания выводится потоковым выводом. Модель запущена на 4090 Ti; средняя пропускная способность генерации: 120 токенов/с. На гифке выше показана реальная скорость распознавания таблицы с рукописным текстом.

Проверка орфографии
И снова преодоление никому не нужных проблем. Существующие системы проверки орфографии мне не понравились. Поэтому были скачаны частоты словоформ и словосочетаний с «Национального корпуса русского языка».
Общий объём корпуса:
| Год | Размер |
|---|---|
| По данным на ноябрь 2011 | 192 689 044 словоформы. |
| По данным на октябрь 2023 | 374 449 975 словоформ. |
Текстовые файлы с словоформами 1-грамм, 2-грамм, 3-грамм, 4-грамм, 5-грамм были объединены в единый ngrams словарь в формате parquet.
При загрузке приложения словарь загружается в память.

После чего доступна проверка орфографии и добавление неизвестных слов в пользовательский словарь. Во первых это красиво и как по мне удобно. При нажатии на слово с ошибкой появляется выпадающий список с предложениями правильных слов.
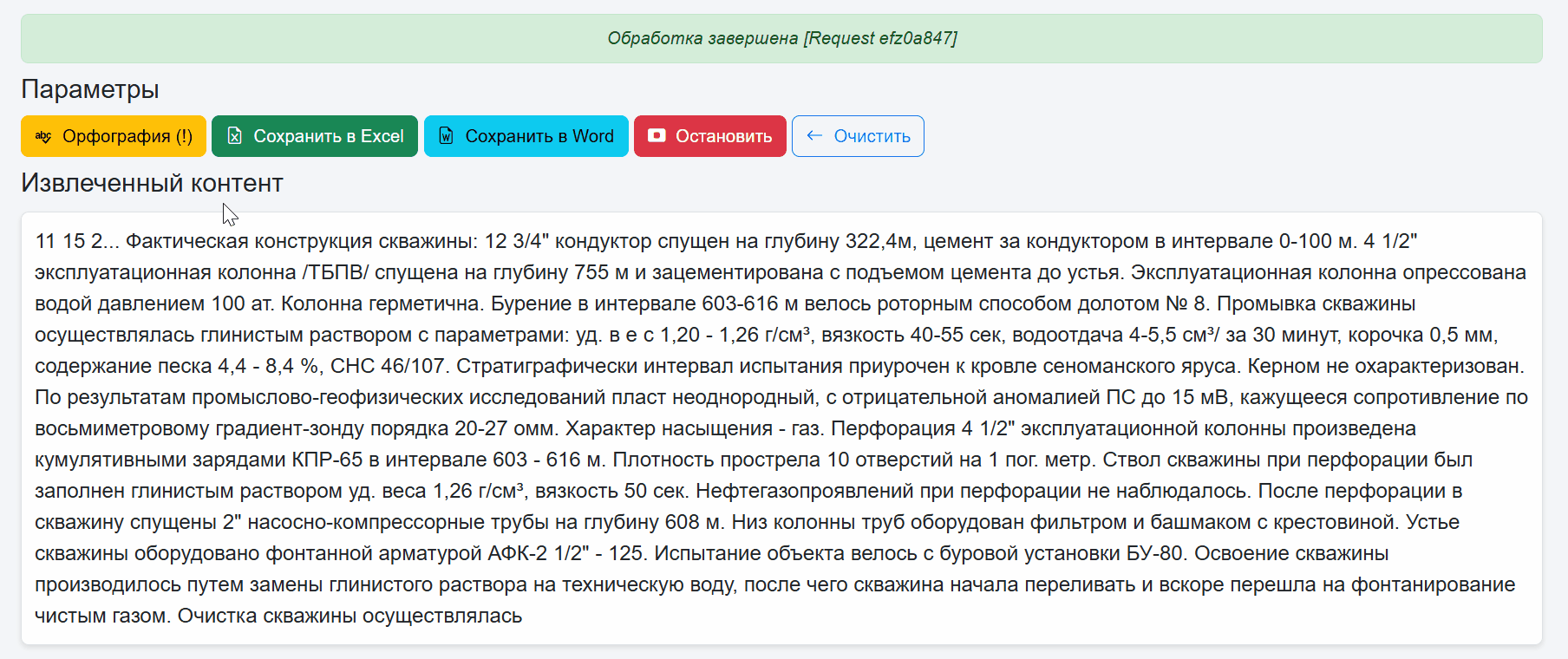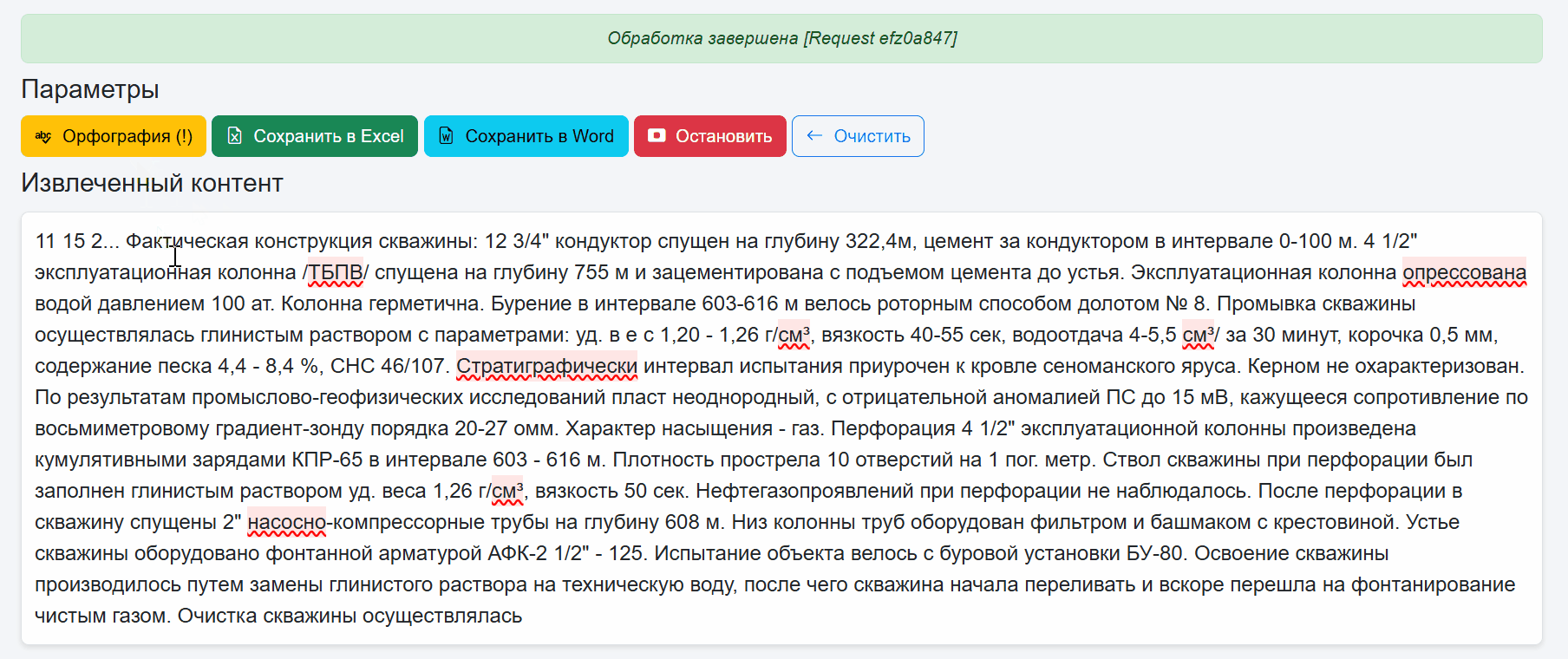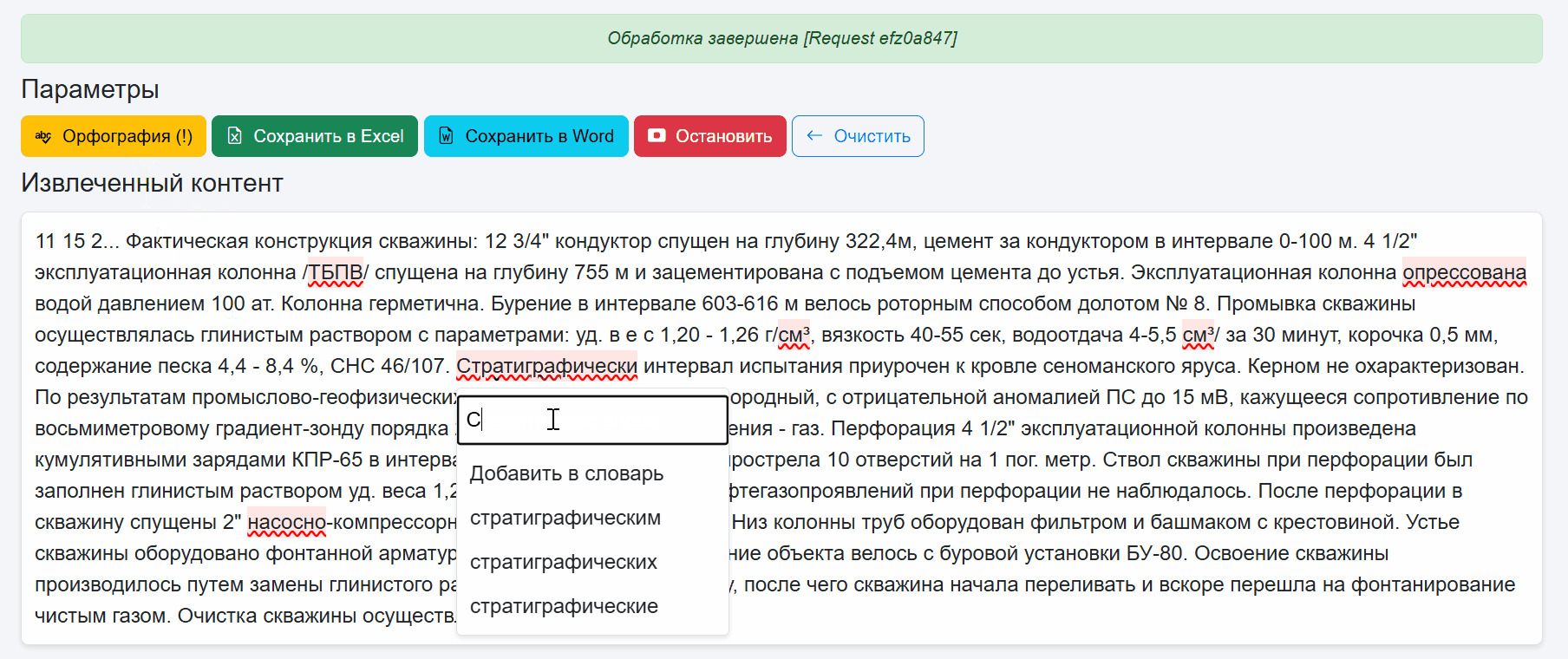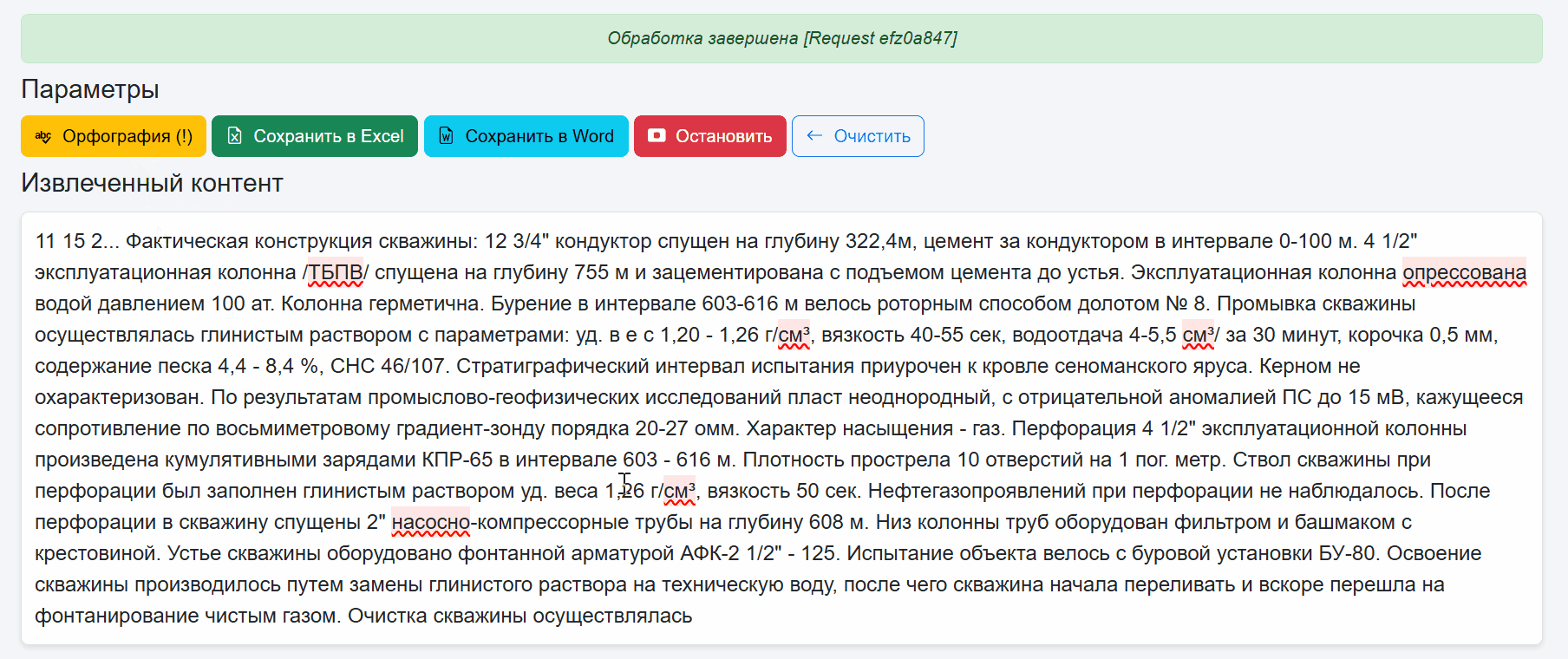
Если слова или словоформы нет, его можно добавить в кастомный словарь.

Выгрузка в Word и Excel
В Word сохраняется текст с максимально приближенным форматированием оригинального документа. В Excel сохраняется структура таблицы с заголовками, столбцами и ячейками.
API эндпоинты и FastAPI маршруты:
- POST
/process-async: Обработка файла, добавление в очередь задач (asyncio.Queue). - GET
/status/{request_id}: Статус задачи, запись в SQLite (для тестов и отладки). - GET
/status: Системный статус. - GET
/save/excel,/save/word: Экспорт. - POST
/check_spelling: Спеллчек. - POST
/add_to_dictionary: Добавление слова.
--
Приложение было написано для распознавания сканов старых документов (50-е + годы), напечатанных на печатных машинках, с чем тот же FineReader не мог справиться, как и другие аналоги. В самом начале силы были брошены на дообучение модели EasyOCR на датасете из собственных и сгенерированных синтетических данных. Улучшения в качестве распознавания были, но тратить время на нарезку и подготовку чистого датасета на собственных данных не было желания. По крайней мере, на данный момент.
--
Обложка для поста любезно нарисована старшим братом — Qwen3-235B-A22B-2507. Хвала Алибабе!
tags: python programming javascript sqlite web ai